
Foundation models in AI: An introduction for beginners
This article demystifies AI foundation models, explaining what they are, common characteristics they share, what they’re capable of doing, and details some well-known examples.

Advancements in AI and machine learning are unfolding at a breathtaking pace. New models, model training techniques, AI products, and startups are hitting the market faster than any sane person can keep track of.
One of the key players behind the staggering speed of advancement in machine learning and AI are foundation models. AI terminology, however, is notoriously nebulous and the term “foundation model” can be hard to define.
This article demystifies foundation models, explaining what they are, common characteristics they share, what they’re capable of doing, and details some well-known examples.
Machine Learning Overview
First, let’s take a step back and briefly review machine learning models in general. The whole point of machine learning is to enable computers to learn from data so that they can be programmed to make decisions or predictions without being specifically programmed to do so. Machine learning models accomplish this by studying the interactions between different individual variables, also called features, and how they affect the outcome for a given data point.
Traditional machine learning models such as linear and logistic regression, decision trees, and random forests require the user to explicitly name the variables, or features, in a model. This process of selecting, transforming, or creating relevant input variables from the available input data is called feature engineering, and can be costly in terms of effort and data required. This is where neural networks come in.
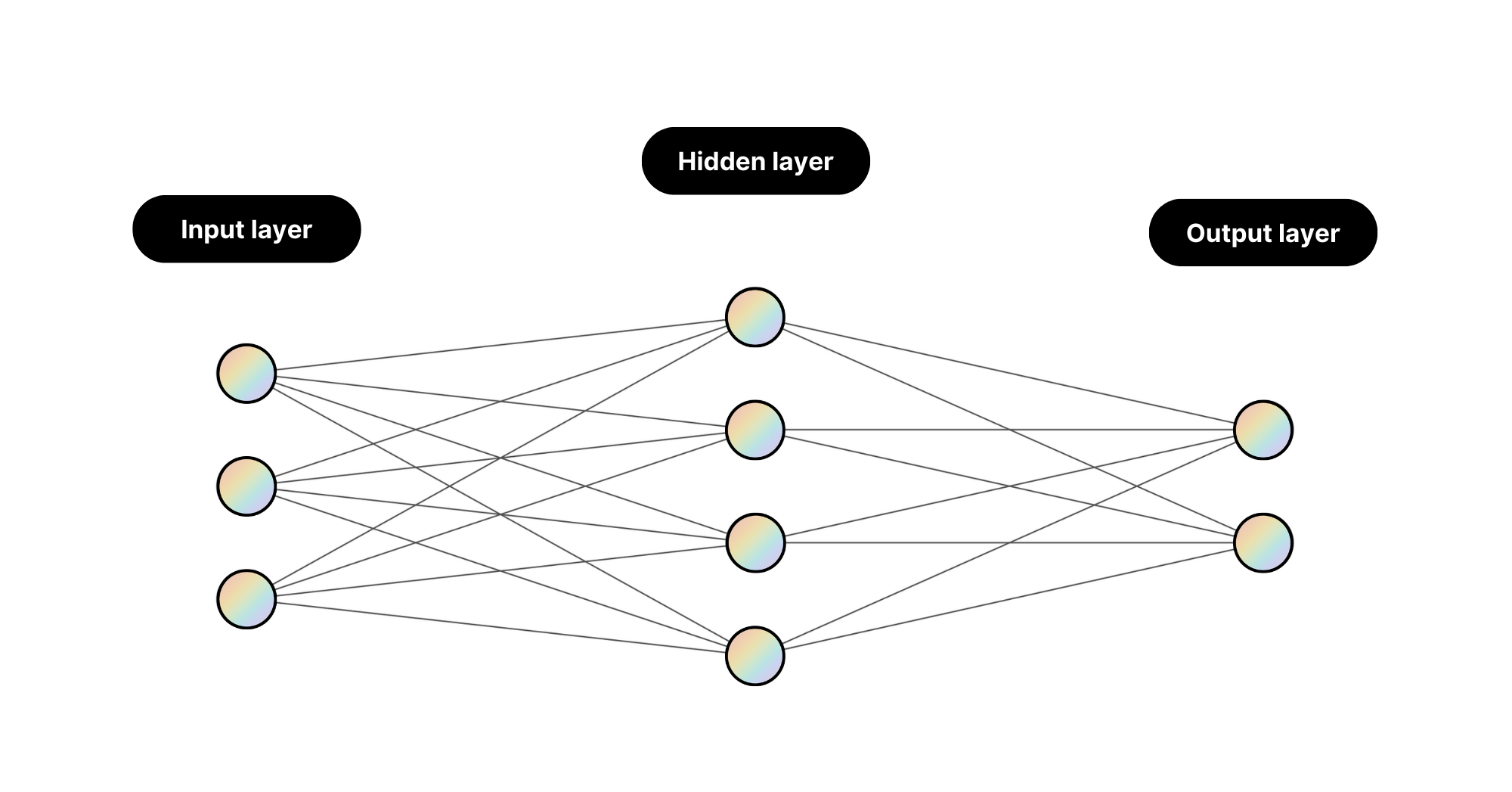
Neural Networks in Machine Learning
A neural network is a predictive model inspired by the structure of the human brain, designed to recognize patterns by processing data through layers of interconnected nodes. What makes neural networks unique from other types of traditional machine learning models is that they learn the features of the data on their own, without any direction or input from the human tasked with training the model. This makes neural networks incredibly powerful statistical tools.
What are foundation models?
A foundation model is a neural network — trained on mountains of unlabeled data usually with specially designed computers — that can be adapted to accomplish a broad range of tasks.
The ability for a single model to perform a variety of tasks is due to the effects of transfer learning, a machine learning method where knowledge gained from one task is applied to another task. And the reason these models perform so well is due to the fact that they are trained on enormous and diverse datasets. One such dataset curated by EleutherAI, called The Pile, is 825GB!
To accommodate such large datasets, pre-training foundation models requires extensive financial and computational resources, which is why most of these models are released by large tech companies or startups with considerable funding. Custom-made supercomputers, sophisticated model architectures, and increasingly, direct feedback and annotations from humans are required to pre-train a state-of-the-art (SOTA) foundation model.
Characteristics of foundation models
While the methods for training foundation models and their training datasets vary considerably, these models maintain several key similarities that can help us better understand what they are and how they work.
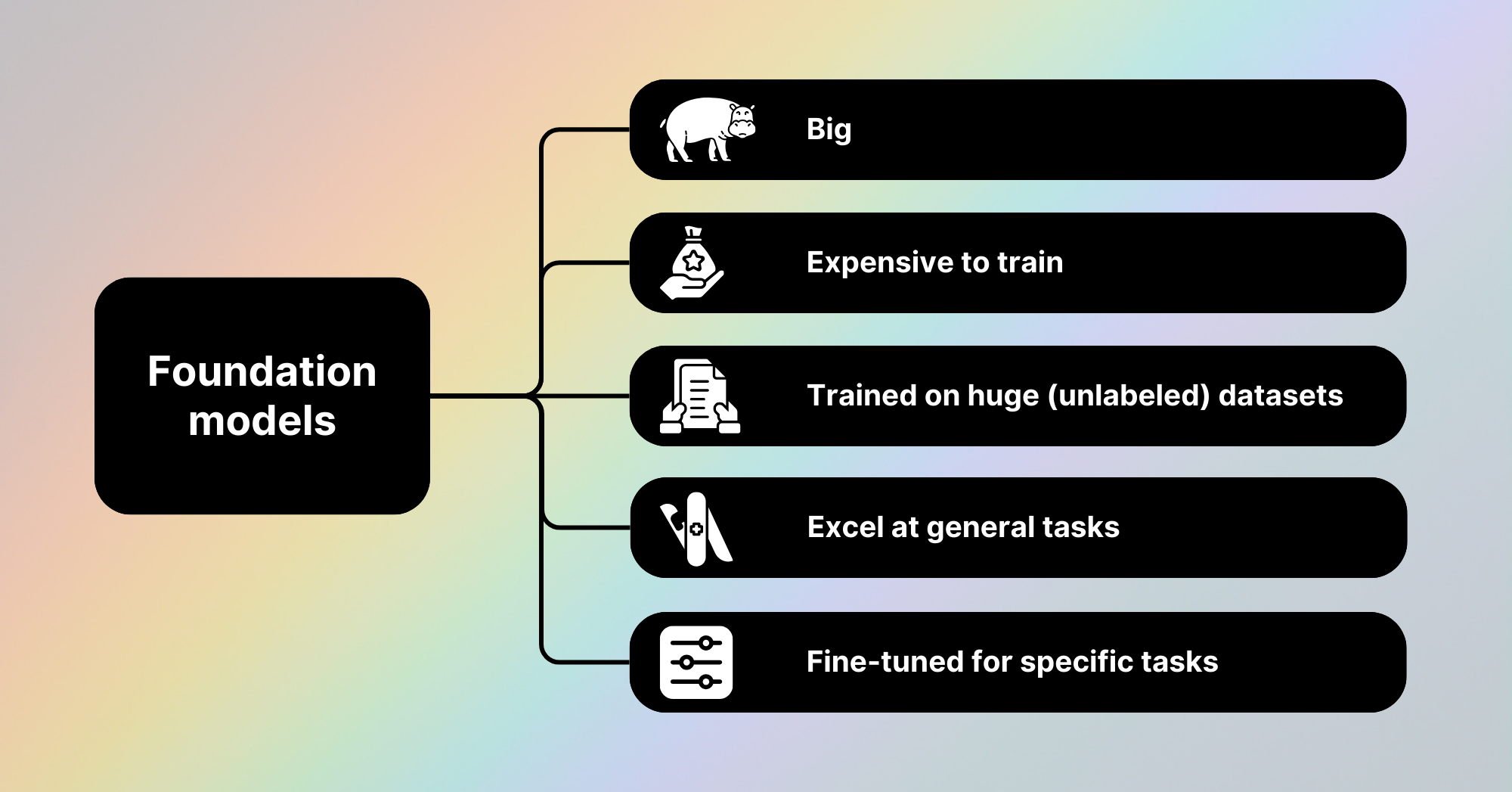
1. Foundation models are big
The relative size of a foundation model is generally determined by its number of parameters. In this context, parameters are the weights and biases of a model adjusted during training to increase its performance. In essence, they store valuable information about relationships in the underlying data the model is trained on and trying to learn from.
Larger models with more parameters are able to perform more detailed and nuanced tasks than smaller models, however, the larger a model is, the more expensive it is to train and and use in production settings. For instance, Meta’s largest version of its Llama-2 model with a whopping 70 billion parameters, is so big that it can’t be loaded into memory on commercial hardware (e.g. a normal laptop or smartphone) and requires significantly cloud computing services. To get around this limitation, many companies that train large foundation models offer API endpoints, which developers to access the model's capabilities remotely, and release models them in a number of different sizes.
2. Foundation models are expensive to train
Due to their characteristically high parameter count, foundation models are costly to train. These models are generally trained using sophisticated, custom-made supercomputing hardware. Microsoft reportedly invested hundreds of millions of dollars to connect tens of thousands of Nvidia A100 chips and reconfigure server racks, creating the advanced hardware that powers ChatGPT and its Bing AI bot.
Foundation models also take a significant amount of time to train from start to finish. Meta’s LLaMA, a large language model with 65 billion parameters released in early 2023, took 21 straight days to train. Big tech companies training closed-source foundation models aren’t always keen to publish certain technical details like training time, number of parameters, or model architecture, but you can be certain that the resources required to train these models are significant.
3. Foundation models are trained on huge (unlabeled) datasets
Traditional supervised machine learning models require labeled training datasets. One such example would be training a model to predict whether an email is spam or not spam by training it on a dataset of real-world examples labeled by humans. Part of what makes foundation models so powerful is their ability to learn patterns and relationships from totally unlabeled datasets. The Common Crawl dataset, which contains over 250 billion scraped webpages spanning the last 17 years, was instrumental in training some of the early foundation models. The diverse nature of these datasets enables foundation models to acquire a general knowledge base that was previously unthinkable with only labeled datasets. Furthermore, in contrast to labeled datasets, which are expensive to curate and annotate, unlabeled datasets are relatively cheap and plentiful to utilize.
4. Foundation models excel at general tasks
Several factors enable foundation models to perform well on general language and image tasks. The size of a model, measured in number of parameters, and the size and diversity of its training dataset are two such factors. The third, is the implementation of transfer learning, a technique in which a model developed for one task is reused as the starting point for a model on a second task, leveraging previously learned features to improve performance or reduce training time.
Foundation models are particularly adept at language translation, text summarization, text style transfer, and image detection. These capabilities allow them to not only understand and generate human-like text but also to recognize and interpret visual content with high accuracy, making them invaluable across a range of applications from automated customer service to content creation.
5. Foundation models are fine-tuned for specific tasks
Although they perform general tasks well, foundation models struggle with specific tasks that require intimate domain knowledge. For example, a vision foundation model may be able to accurately distinguish between pictures of dogs and cats but would certainly struggle in distinguishing between cancerous and non-cancerous medical images for a rare form of brain cancer. This is because these models lack the specialized training on the subtle, specific features critical to such niche medical diagnostics.
However, the principles of transfer learning enable the creation of smaller models that are trained on more focused, domain-specific datasets while still inheriting substantial knowledge from larger foundation models. This process, called fine-tuning, is highly efficient, accessible, and affordable, making it an excellent option for leveraging the power of expensive foundation models to accomplish niche and business-specific tasks.
Now, let’s look at a few examples of well-known foundation models.
Examples of foundation models
With all the hype surrounding OpenAI’s GPT models, it’s easy to assume that foundation models can only perform tasks related to text and language. However, foundation models span a diverse range of mediums, including text, images, audio, and integrated multimodal data. Some of the most well-known and influential examples of foundation models include GPT, BERT, and diffusion models.
OpenAI's GPT Series
Perhaps the most famous of foundation models, the Generative Pre-trained Transformer (GPT) series of models broke into the mainstream in late 2022, with the release of ChatGPT. The initial release of ChatGPT was powered by the GPT-3.5 foundation model. Since then, OpenAI has released the multimodal GPT-4, its newest foundation model that’s capable of receiving text and image as prompts and generating them as responses.

GPT models particularly excel in generative language tasks, such as text generation, translation, and question-answering. Their ability to generate coherent and contextually relevant text has led to their deployment in applications that specialize in chatbots, content creation, and even coding assistance.
BERT Models
Developed by Google and first released in 2018, BERT (Bidirectional Encoder Representations from Transformers) revolutionized the way machines understand the context within a sentence. Unlike traditional models that read text in one direction, BERT analyzes text bidirectionally, capturing nuances that might be missed otherwise.
Variants of BERT, like RoBERTa and DistilBERT, have further refined and optimized this approach. BERT models aren’t usually used for language generation, like GPT models, but are used primarily for text classification, sentiment analysis, question answering, and named entity recognition.
Diffusion Models
Diffusion models are capable of generating images and videos based on an instructive text prompt. These models are trained by gradually degrading a set of images in a dataset until they are unrecognizable and then teaching themselves how to reconstruct the images. While diffusion models have been around since 2015, the release of the Stable Diffusion model by Stability AI in 2022 marked a turning point in the quality of model output, setting new standards for realism and detail.
Other well-known models, such as Midjourney, Sora, and the Dall-E models, are primarily used for image and video generation. By using descriptive text prompts, these models can be used to create totally novel images and videos or edit and refine existing ones.
Conclusion
Foundation models are neural networks trained on huge unlabeled datasets that can be adapted to perform a broad range of tasks. These models are large, oftentimes made up of billions of parameters and are expensive and complex to train. They perform very well on general tasks and can be fine-tuned on smaller, more targeted datasets to accomplish more specific, nuanced tasks.
Foundation models that receive text as their inputs and outputs are called LLMs and can be used for text generation, summarization, classification, language translation and a variety of other language tasks. Foundation models that generate images or videos are called vision models and can be used to create novel content or edit existing content, usually with the help of an instructive text prompt.
If you want to dive deeper into the uses and architectures of foundation models, be sure to check out our post on Transformer and diffusion models.
Sources
- Meta. (2023, July 18). Llama 2: Open Foundation and Fine-Tuned Chat Models. Meta.
- Roth, E. (2023, May 13). Microsoft spent hundreds of millions of dollars on a ChatGPT supercomputer. The Verge.
- Newhauser, M. (2023, July 13). The two models fueling generative AI products: Transformers and diffusion models. GPTech.
- Meta. (2023, February 24). Introducing LLaMA: A foundational, 65-billion-parameter large language model. Meta.
- Common Crawl. (2024). Common Crawl - Open Repository of Web Crawl Data. Common Crawl.
- Ferrer, J. (2024, February). An Introductory Guide to Fine-Tuning LLMs. DataCamp.
- OpenAI. (2022, November 30). Introducing ChatGPT. OpenAI.
- Open AI. (2023, March 14). GPT-4. OpenAI.
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., Stoyanov, V. (2019, October 2). RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv.
- Devlin, J., Chang, M.-W., Lee, K., Toutanova, K. (2018, October 11). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv.
- Alammar, J. (2018, December 3). The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning). Jay Alammar
- Stability AI. (2022, August 22). Stable Diffusion Public Release. arXiv.
- OpenAI. (2024, February 15). Sora. OpenAI.
- OpenAI. (2023, August 20). Dall-e 3. OpenAI.
📝 What it Takes to Train a Foundation Model (No Code AI)
📁 Awesome-Foundation-Models repo
📄 On the Opportunities and Risks of Foundation Models (Stanford)